Fast food, causality and R packages, part 1
R

I am currently working on a package for the R programming language; its initial goal was to simply distribute the data used in the Card and Krueger 1994 paper that you can read here (PDF warning).
The gist of the paper is to try to answer the following question: Do increases in minimum wages reduce employment? According to Card and Krueger’s paper from 1994, no. The authors studied a change in legislation in New Jersey which increased the minimum wage from $4.25 an hour to $5.05 an hour. The neighbourghing state of Pennsylvania did not introduce such an increase. The authors thus used the State of Pennsylvania as a control for the State of New Jersey and studied how the increase in minimum wage impacted the employment in fast food restaurants and found, against what economic theory predicted, an increase and not a decrease in employment. The authors used a method called difference-in-differences to asses the impact of the minimum wage increase.
This result was and still is controversial, with subsequent studies finding subtler results. For instance, showing that there is a reduction in employment following an increase in minimum wage, but only for large restaurants (see Ropponen and Olli, 2011).
Anyways, this blog post will discuss how to create a package using to distribute the data. In a future blog post, I will discuss preparing the data to make it available as a demo dataset inside the package, and then writing and documenting functions.
The first step to create a package, is to create a new project:
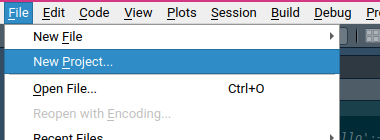
Select “New Directory”:
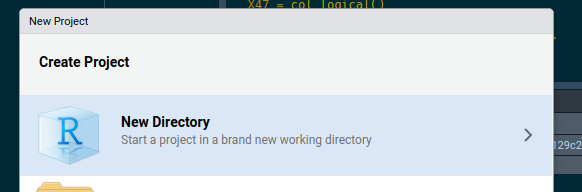
Then “R package”:

and on the window that appears, you can choose the name of the package, as well as already some starting source files:
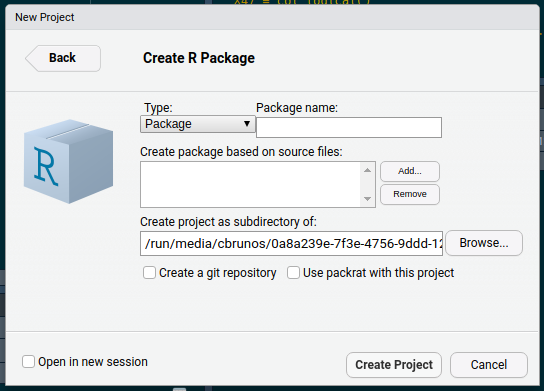
Also, I’d highly recommend you click on the “Create a git repository” box and use git within your project for reproducibility and sharing your code more easily. If you do not know git, there’s a lot of online resources to get you started. It’s not super difficult, but it does require making some new habits, which can take some time.
I called my package {diffindiff}, and clicked on “Create Project”. This opens up a new project
with a hello.R script, which gives you some pointers:
# Hello, world!
#
# This is an example function named 'hello'
# which prints 'Hello, world!'.
#
# You can learn more about package authoring with RStudio at:
#
# http://r-pkgs.had.co.nz/
#
# Some useful keyboard shortcuts for package authoring:
#
# Install Package: 'Ctrl + Shift + B'
# Check Package: 'Ctrl + Shift + E'
# Test Package: 'Ctrl + Shift + T'
hello <- function() {
print("Hello, world!")
}Now, to simplify the creation of your package, I highly recommend you use the {usethis} package.
{usethis} removes a lot of the pain involved in creating packages.
For instance, want to start by adding a README file? Simply run:
usethis::use_readme_md()✔ Setting active project to '/path/to/your/package/diffindiff'
✔ Writing 'README.md'
● Modify 'README.md'This creates a README.md file in the root directory of your package. Simply change that file, and that’s it.
The next step could be setting up your package to work with {roxygen2}, which is very useful for
writing documentation:
usethis::use_roxygen_md()✔ Setting Roxygen field in DESCRIPTION to 'list(markdown = TRUE)'
✔ Setting RoxygenNote field in DESCRIPTION to '6.1.1'
● Run `devtools::document()`See how the output tells you to run devtools::document()? This function will document your package,
transforming the comments you write to describe your functions to documentation and managing the NAMESPACE
file. Let’s run this function too:
devtools::document()Updating diffindiff documentation
First time using roxygen2. Upgrading automatically...
Loading diffindiff
Warning: The existing 'NAMESPACE' file was not generated by roxygen2, and will not be overwritten.You might have a similar message than me, telling you that the NAMESPACE file was not generated by
{roxygen2}, and will thus not be overwritten. Simply remove the file and run devtools::document()
again:
devtools::document()Updating diffindiff documentation
First time using roxygen2. Upgrading automatically...
Writing NAMESPACE
Loading diffindiffBut what is actually the NAMESPACE file? This file is quite important, as it details where your
package’s functions have to look for in order to use other functions. This means that if your package needs function
foo() from package {bar}, it will consistently look for foo() inside {bar} and not confuse
it with, say, the foo() function from the {barley} package, even if you load {barley} after
{bar} in your interactive session. This can seem confusing now, but in the next blog posts I will
detail this, and you will see that it’s not that difficult. Just know that it is an important file,
and that you do not have to edit it by hand.
Next, I like to run the following:
usethis::use_pipe()✔ Adding 'magrittr' to Imports field in DESCRIPTION
✔ Writing 'R/utils-pipe.R'
● Run `devtools::document()`This makes the now famous %>% function available internally to your package (so you can use it
to write the functions that will be included in your package) but also available to the users that
will load the package.
Your package is still missing a license. If you plan on writing a package for your own personal use, for instance, a collection of functions, there is no need to think about licenses. But if you’re making your package available through CRAN, then you definitely need to think about it. For this package, I’ll be using the MIT license, because the package will distribute data which I do not own (I’ve got permission from Card to re-distribute it) and thus I think it would be better to use a permissive license (I don’t know if the GPL, another license, which is stricter in terms of redistribution, could be used in this case).
usethis::use_mit_license()✔ Setting License field in DESCRIPTION to 'MIT + file LICENSE'
✔ Writing 'LICENSE.md'
✔ Adding '^LICENSE\\.md$' to '.Rbuildignore'
✔ Writing 'LICENSE'We’re almost done setting up the structure of the package. If we forget something though, it’s not an issue,
we’ll just have to run the right use_* function later on. Let’s finish by preparing the folder
that will contains the script to prepare the data:
usethis::use_data_raw()✔ Creating 'data-raw/'
✔ Adding '^data-raw$' to '.Rbuildignore'
✔ Writing 'data-raw/DATASET.R'
● Modify 'data-raw/DATASET.R'
● Finish the data preparation script in 'data-raw/DATASET.R'
● Use `usethis::use_data()` to add prepared data to packageThis creates the data-raw folder with the DATASET.R script inside. This is the script that will
contain the code to download and prepare datasets that you want to include in your package. This will
be the subject of the next blog post.
Let’s now finish by documenting the package, and pushing everything to Github:
devtools::document()The following lines will only work if you set up the Github repo:
git add .
git commit -am "first commit"
git push origin masterHope you enjoyed! If you found this blog post useful, you might want to follow me on twitter for blog post updates and buy me an espresso or paypal.me.